AuraQ has vast experience helping organisations find the gaps that can be filled to enhance their business. This could be to improve efficiency, integrate legacy systems or deliver new portals and strategic applications to create competitive advantage. Contact us to request a free, no obligation Gap Analysis.
21st Apr 2017
Retrieving data in Mendix
Mendix Applications databases can contain large amounts of valuable information, and so it is important that care is taken when retrieving data from them. Constantly pulling large amounts of data from the database will cause an Application to slow down.
Beyond performance, there are also data protection and security reasons why an Application should not be accessing information from the database when it does not need to.
Developers need to think carefully when retrieving in their microflows, datagrids and java actions. A well designed Mendix application will make use of the client memory, associations and XPath constraints to only retrieve information from the database when necessary.
One of the simplest ways to reduce the amount of data being retrieved from the database is to make good use of data already in the client. It is much faster to access data that is on the client than to pull it from a large database stored on a server.
Mendix automatically checks to see whether the information is available in the client before searching the database. This is a useful feature, however whenever possible the number of Retrieves should be cut down as there is still a chance that they could access information from the database. If objects are used more than once in a microflow, then instead of retrieving the same objects each time, the objects should be retrieved once and the Retrieve’s variable should be reused.
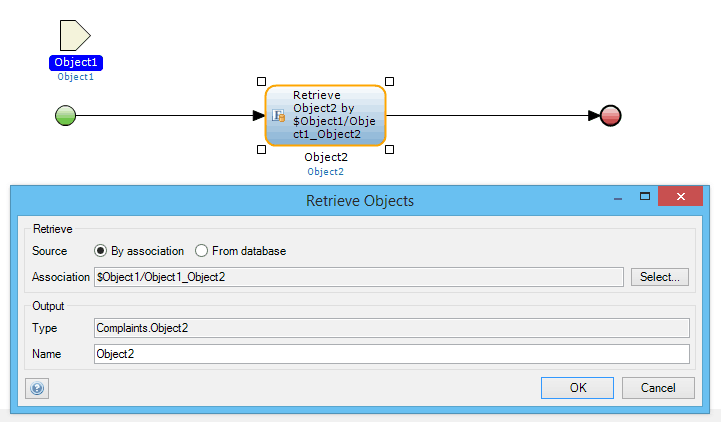
One way to make use of the client is by retrieving data through associations. If you use a reference object that is already in the client, you will be able to retrieve objects associated with it more efficiently than if you searched the database without any reference.
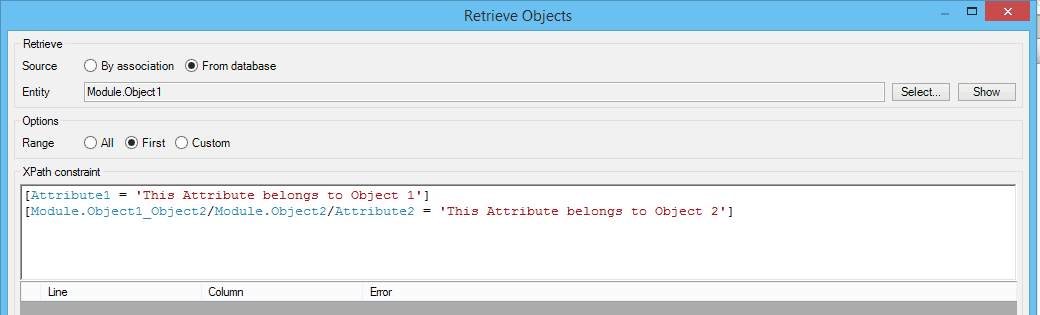
If it is not possible to retrieve information through an associated object then XPaths can be used to search the database. XPath is a query language that allows the user to create path expressions that retrieve data efficiently from the databases. Mendix supports a number of XPath functions and constraints that allow the developer to retrieve only the data needed from the database. This prevents the Application from wasting memory retrieving unnecessary data.
For example, if you wanted to only retrieve Mendix Objects that belonged to the current user and were less than a week old you could use the following expression; [System.Owner = Current.User][DateCreated >= BeginOfCurrentWeek].
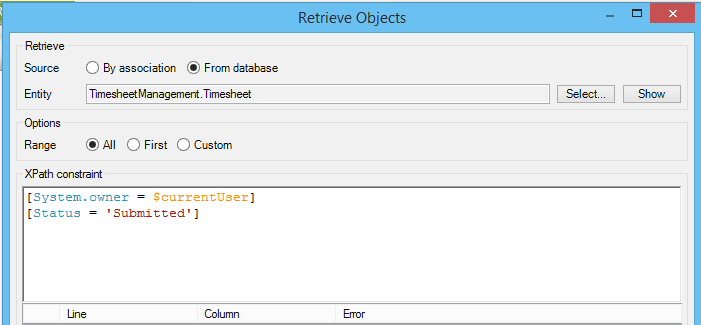
To make Xpath Retrieves more efficient it is good practice to order constraints so that the most restrictive constraint is first. If there were thousands of timesheets in the system and you wanted to retrieve all the timesheets that a user had submitted, then you would want your first constraint to be the one that narrowed down the number of timesheets the most. The most restrictive constraint may vary depending on the size of the company and the percentage of timesheets that have been submitted.
Therefore it helps to have a good understanding of the company for which you are designing the Application. In a company with 100 employees, where half the timesheets have been submitted, instead of searching all 1000 timesheets’ statuses to narrow down the search to 500–then needing to search each of those 500 timesheets again for the correct user–you would want to retrieve all the timesheets of an employee, narrowing the number of timesheets from 1000 to say, 10, before searching each of those timesheets statuses.
As well as being able to retrieve an object based on its attribute values, it is also possible to retrieve an object based on its associations, whether it be through a single association, i.e. [Contacts.Address_Employee/ Contacts.Address/Town = ‘Malvern’]’, or through multiple associations, i.e. ‘[Contacts.Address_Employee/ Contacts.Address/Town = ‘Malvern’ or Training.Contacts_Address/ Contacts.Address/County = ‘Worcestershire’].
Whenever comparing two attributes of the same associated object, you should avoid going through the same association twice. Instead, once you have referenced the object the first time, you should then check both the attributes. So in microflows, when comparing two values from the same associated object, group the comparisons together using ‘[]’. I.e. ‘[Contacts.Address_Employee/Contacts.Address [Town = ‘Malvern’ or County = ‘Worcestershire’]]’.
This also applies to pages that show multiple attributes of the same associated object in Mendix.
It is good practice to place all the fields in a nested data view under the same object, as it prevents each field from going through the same association each time it needs retrieve an attribute.
In Xpath, when both sides follow an association, avoid ‘OR’ statements. If you wanted to retrieve all timesheets that had the status either ‘Submitted’ or ‘Archived’, as this will make it more efficient to retrieve all the timesheets that had the status ‘Submitted’, then all the timesheets that had the status ‘Archived’, and combine them together using a Union, rather that going through every single leave and checking that it belonged to either ‘Submitted or ‘Archived’ at the same time.

Another thing to look out for when using an association in the not() function, is the not function will return true if anything in the path is not true. So if the Employee has no associated addresses, the route would be untrue meaning the Xpath would return true, (i.e. [not(Contacts.Address_Employee/ Contacts.Address/Postcode = ‘WR14 1AB’)]). Unlike with the ‘!=’ operator, which returns false unless the value on the left of the operator is not equal to the value on the right. [Contacts.Address_Employee/ Contacts.Address/Postcode != ‘WR14 1AB’ ] would return false, as there is no address.
The design of a page can also help reduce the amount of data being retrieved. For example reducing the number of editable dropdowns (reference selectors) on a page will also help reduce the amount of data being pulled from the database, as each dropdown triggers it’s own ‘retrive list’ action. Dropdowns can be replaced with popup windows, with search with search filters, that will only retrieve the relevant information.
While the need to efficiently retrieve data may vary between Applications, it is important to think about how you are retrieving data. This is because even if you may not notice a difference in speed now, databases can grow, whether it be through accumulating more data over time or by the company expanding in size. While an Application may run fine on a small database, with only a few gigabytes worth of information, this can change. You don’t want to be wasting memory and time retrieving gigabytes of information unnecessarily.
Related Blogs




Drag