AuraQ has vast experience helping organisations find the gaps that can be filled to enhance their business. This could be to improve efficiency, integrate legacy systems or deliver new portals and strategic applications to create competitive advantage. Contact us to request a free, no obligation Gap Analysis.
15th Jun 2018
Optimising Mendix when handling large volumes of data
Often during Mendix development, a developer will come across a query to the database which is badly optimised. This is usually caused by complex business requirements and time restrictions. Below will go into an example of a badly optimised query and how to tackle these moving forwards to ensure that the execution times are optimal.
A business requirement for a project was to create a custom search that would return a list of contract objects that met the given criteria. The first implementation of this custom search was very straightforward and got the job done but when the search was being thoroughly tested using a realistic amount of data, the query was taking way too long – up to 100 seconds! If this query was left to run in the background it wouldn’t have been a problem, but as this was the result of a user clicking a button the hang time was adversely affecting the user experience. The search button had to be refactored.
Here’s a look into how the search time was cut from 100 seconds to averaging 2-5 seconds whilst being run against a large volume of data.
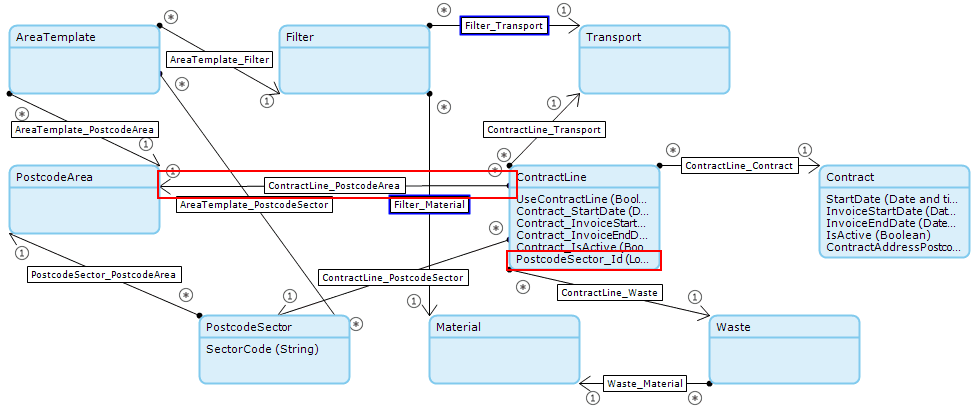
This is a simplified version of the domain model that was being used:
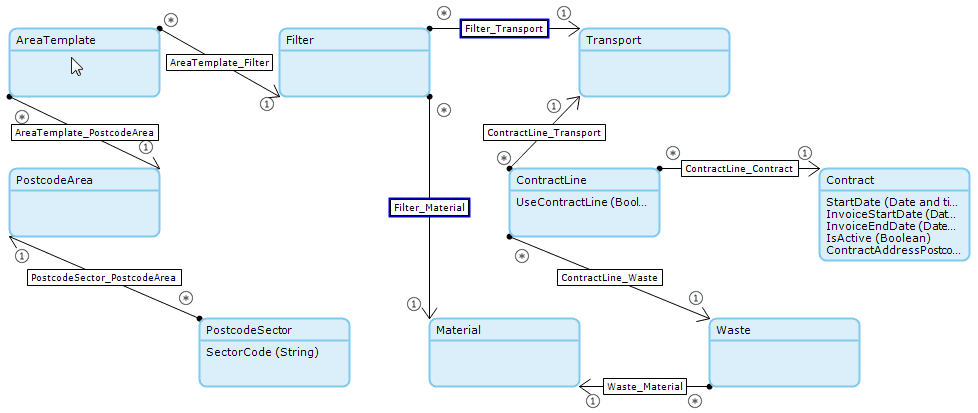
There are three filters to this search:
- Transport
- Material
- Area Template(s)
Transport and material were straightforward dropdowns for the search as they were relevant to data already in the database. The area template filter came with a challenge; the user had to be able to add a specific postcode area with selected sectors that are inside that area (based on the UK’s postcode area, district, and sector system). More than one area could be added to the search and as there are anywhere from 10-100 postcode sectors in an area, several area templates would result in a rapid increase in the total sectors being searched on.
Initial Mendix Implementation
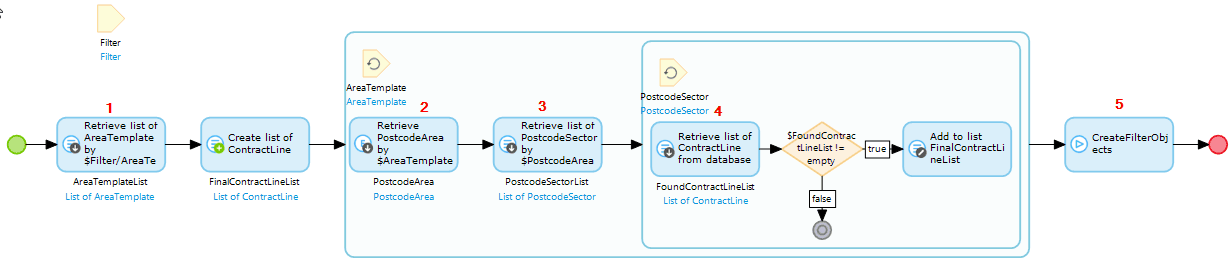
1. Retrieve all the area templates selected.
2. Each area template would then retrieve their postcode area.
3. Each postcode area then retrieves all its sectors.
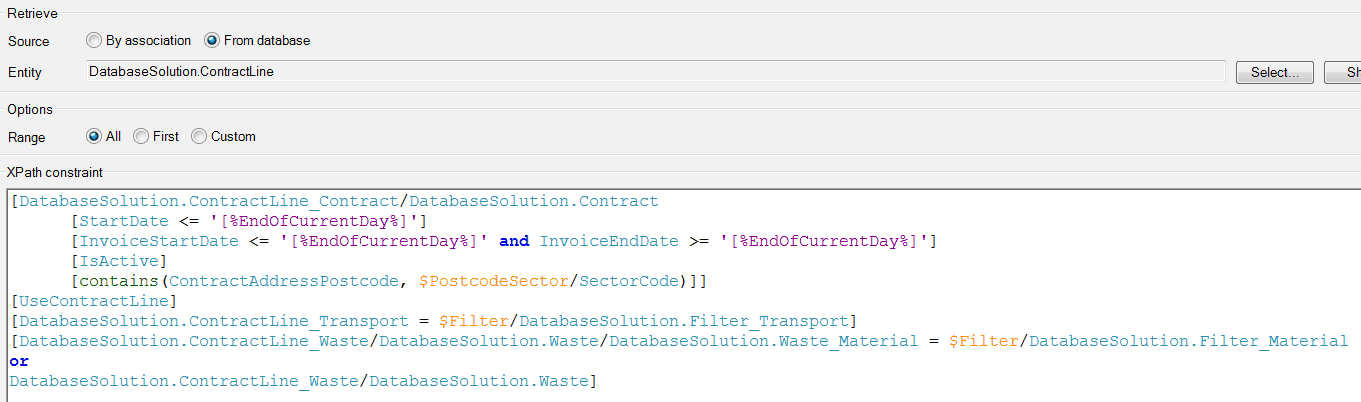
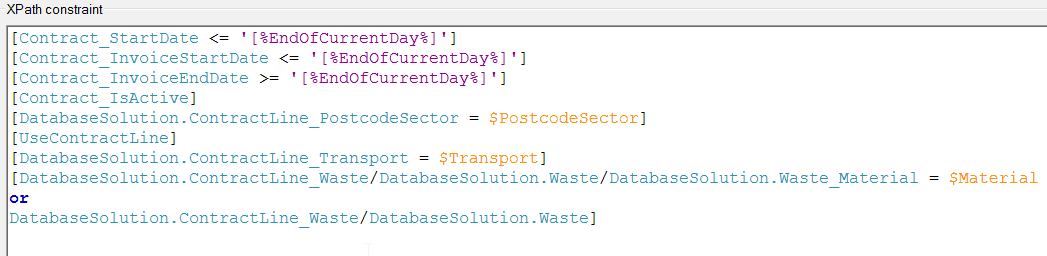
4. Iterating on each sector the following XPath constraint would be applied:
5. After each sector has been iterated through return the list of contract lines.
The XPath constraint above has eight constraints that are all necessary to return the correct list of contract line objects. The problem with the top four constraints at a glance was that they were all having to check through the ContractLine_Contract association to the attributes on the contract object. Also, having to loop on each area template and sector took a fair amount of time when there were multiple area templates with 10s of sectors selected.
The following changes were applied to optimise the microflow:
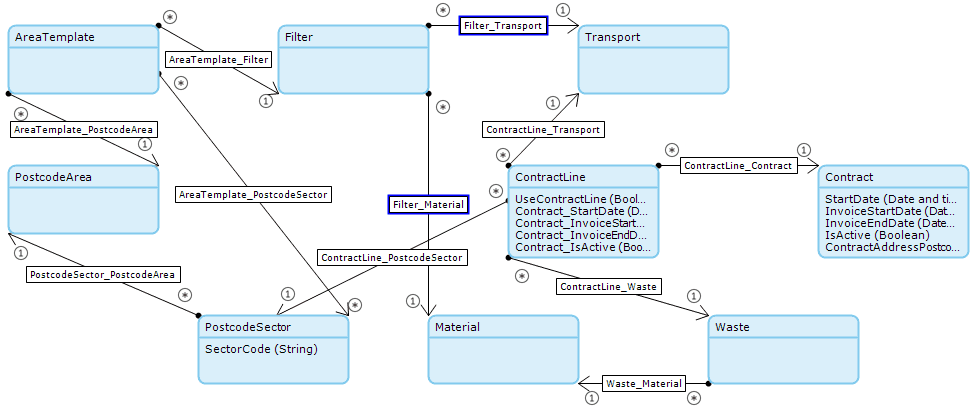
- Denormalizing the contract data into contract line. Denormalization is the process of trying to improve the read performance of a database, at the expense of losing some write performance, by adding redundant copies of data or by grouping data. In this case, moving the contract data down to the contract line.
- AreaTemplate_PostcodeSector association added. This will be used to avoid having to do the initial postcode area retrieve each time.
- Removing one of the loops. Nested loops are to be avoided as mentioned in the Mendix best practices and here the service zone area loop was removed. Postcode sectors can now be retrieved using the new associations that was added above.
- ContractLine_PostcodeSector association added. This will remove the contains(ServiceAddressPostcode, $PostcodeSector/SectorCode) query as part of the XPath.
Denormalizing Data and Applying Associations
Here is a look at the updated domain model with the above changes:
And a new looking microflow was created based on these changes:
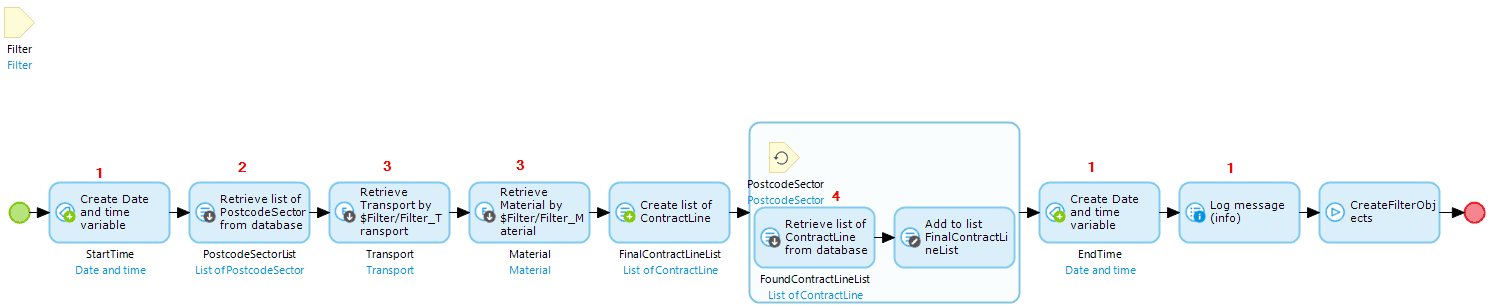
1. Added in some logging for debugging purposes.
2. Postcode sectors are now retrieved right at the beginning using the new association that was added between area templates and postcode sectors. 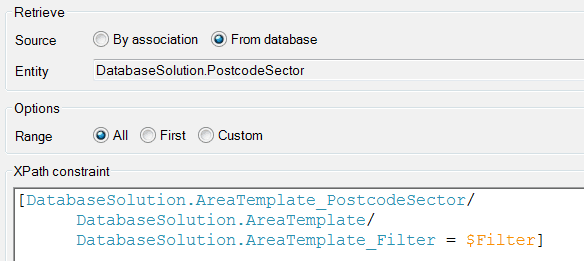 3. Transport and Material are retrieved once at the beginning of the microflow and referred to in the database retrieve instead of having to do the retrieve each time.
3. Transport and Material are retrieved once at the beginning of the microflow and referred to in the database retrieve instead of having to do the retrieve each time.
The updated database retrieve using the denormalized data:
By denormalizing the data and moving the contains to a new association the query time had been reduced to around 15-18 seconds. This was a huge improvement considering the initial 100 second wait period, but a 15 second wait is still quite a long time from a user experience perspective. The reason it was still taking such a long time was because of the loop on the post code sectors – 10-100 sectors per area means that this would only get worse; the current solution wasn’t scalable.
Further Denormalizing and Java action Memory Filtering It was obvious that the amount of postcode sectors is what is affecting the length of the query, so the last part of the solution was to remove the looping on the postcode sectors. To remedy this, implementing some Java code that would use memory filtering on the postcode sectors seemed like a feasible option; a few more changes needed to be applied to the domain model before this could be done.
A new association was added between postcode area and contract line, and the postcode sector ID was denormalized to contract line. This new ID is what enabled the contract lines to be filtered against the list of postcode sectors in memory using the below code in a Java action:
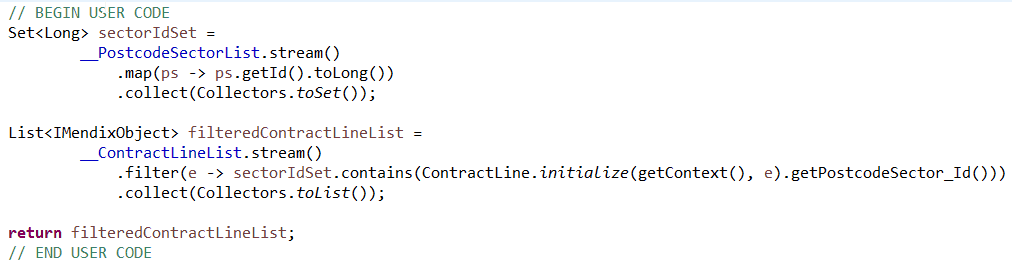
The Java action required passing in a list of postcode sectors and contract lines, it would then filter the contract lines ID against the IDs of the objects in the postcode sector list, finally it would return a list of the contract lines that meet all the prior selected search criteria.

This is what the final iteration of the microflow looks like, making sure to lose the postcode sector loop. It has also moved back to the original area template loop of the original microflow. From a business use perspective, there was to be between one and five areas selected, so five iterations weren’t going to be too bad on query times. There are still a few necessary retrieves in the loop, but these are all needed within the contract line database retrieve and the memory filtering java action:

The final microflow reduced the query time down to about two seconds per query. This was a huge success in the eyes of the of the product owner and they were happy with the results of the optimisation.
The first thought was to reduce the amount of database calls. This was successful, but due to the amount of data that was being handled, another part had to be added to the solution. Usually when creating an application, having denormalized data is something would be good to avoid. As shown, having to aggregate on large amounts of data can affect such scenarios and the data had to be denormalized as part of a feasible solution. Furthermore, applying good usages of associations between entities makes retrieving a lot less process intensive as the retrieves in Mendix are optimised with associations in mind. Although, even after denormalizing there was still a problem in terms of user experience. Further optimisation in this part was done by applying memory filtering using two lists to eliminate the need for iterating on one of the lists objects.
Related Blogs




Drag