AuraQ has vast experience helping organisations find the gaps that can be filled to enhance their business. This could be to improve efficiency, integrate legacy systems or deliver new portals and strategic applications to create competitive advantage. Contact us to request a free, no obligation Gap Analysis.

10 favourite Mendix bugs – lessons learned from a year of low-code development
In order to integrate an MBA I had to pass the GMAT exam, which includes amongst other things English essays. The scoring mechanism for the writing was somewhat obscure, but one thing that was clear is that many points were deducted for spelling mistakes. Basically, make more than three spelling mistakes in the essay, and you were out. English is not my mother tongue, and trying to achieve this without Microsoft Word was humbling…To improve my spelling, I used a technic from my high school days. A teacher told me that to make meaningful progress, in his words, I had to “heal faster”. What he meant by that was a simple and very effective rule:
“Make a mistake, write it down, memorise it, don’t make it again.”
This works surprisingly well. After a few rounds of iteration, I’d built up a list of 100 common spelling mistakes. As it turns out, they represented 90% of the mistakes I ever made. I soon realised that I had been making the same mistakes over and over again. While it seems impossible to memorise the entire English language quickly, it is surprisingly achievable to go under three mistakes per essay within a couple of weeks of practice.
My 10 favourite Mendix bugs
After more than a year of Mendix development, I decided it was time to go through dozens of items of testing feedback, in order to prepare a list of the bugs I make the most, and which I should never make again. Some of those might be useful for you, but the point is to encourage you make your own list in order to “heal faster”.
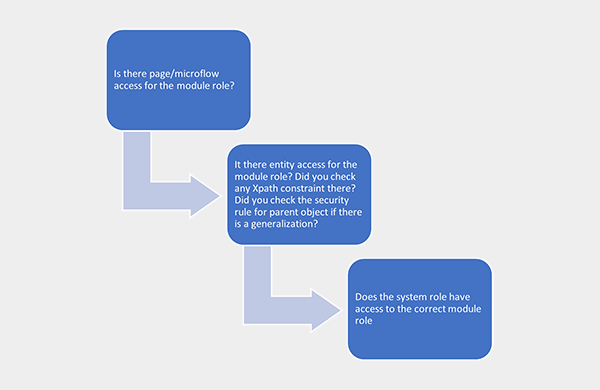
1. Security
It is almost a running joke in the team – if anybody comes to one of us with a problem, more often than not the first question we ask is “Have you checked security?” And inevitably, it turns out to be the problem. This is my check-list and this is how I set up module roles:
- For reusable modules, keep it generic; for instance; Admin, User, Read-Only.
- For application specific modules, keep it generic as well if you can (Admin, Read-Only, etc.) and if you can’t, just add the exact same roles you have as system roles (i.e. Customer, Supplier, etc.)
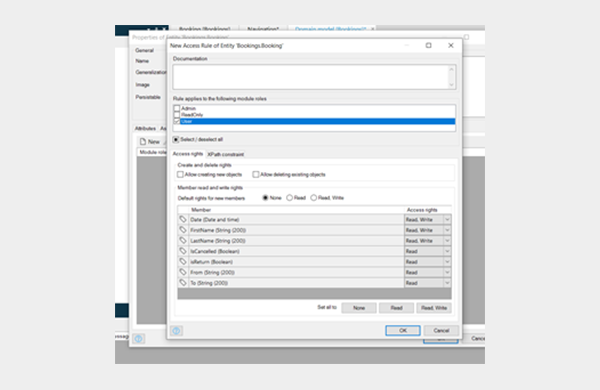
To keep it tidy, what I suggest is to grant access to entities on a need-to-know basis. Start with no-read, no-write to all attributes, and progressively add the rights to read and write data as required by the business requirements. As tempting as it is, try to refrain from pressing that “Read, Write” button granting universal access.
2. Date and time
Date and time is another fertile ground for bugs. Most of my bugs have come from customers working over different time zones. Imagine this: user John makes a booking in the Mendix app from his office in San Francisco. The booking date shown to him on screen is 09/07/2020. In reality, the system is storing something like:
- Local: 09/07/2020 18:47
- UTC: 10/07/2020 01:47
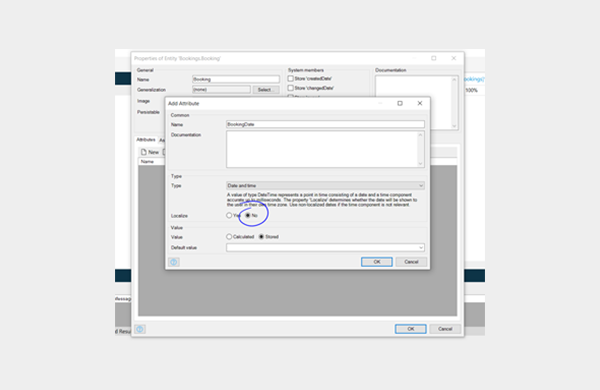
Now when I look at the same date on my screen in London, what I see is 10/07/2020. That’s because San Francisco is 7 hours behind UTC and London 1 hour ahead of UTC. In this case, we don’t care about the time, only the date: On the attribute, select Localize: No (this means that both me and John will interact with times expressed in UTC).
- On each date and time functions, make sure to use UTC. For instance, if I want to create a return trip seven days later, instead of using addDays($booking/BookingDate, 7) I need to use addDaysUTC($booking/BookingDate, 7). This ensures the new date is built on the UTC value +7 , not the local value.
- Be careful when sending email, generating documents, sending data out by API. Always make sure you make a conscious decision to choose UTC or local time depending on the use case.
3. Empty retrieves
That’s an easy one. I am retrieving data and performing a calculation with it and I get the below error:
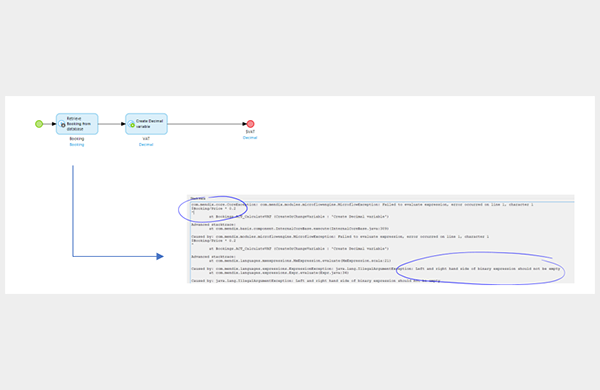
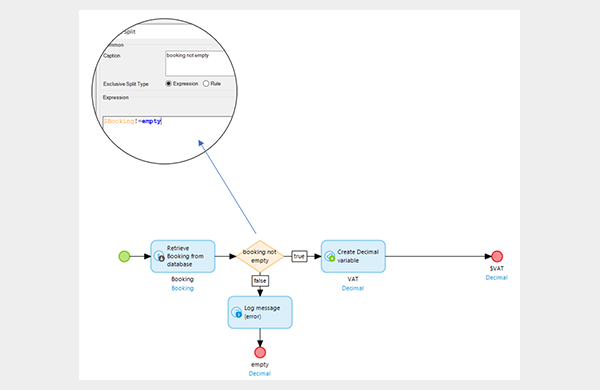
This occurs because no object could be retrieved, for whatever reason. It is easy to spot here because the microflow is so simple, but sometimes a failed retrieve will have an impact three sub-microflows down, and it can take a while to retrace steps and find why data is missing in the first place. The simple solution is to always check for value after each retrieve as above.
4. Divide by zero
Another simple one. The bug occurs during a calculation, when the divisor happens to be null. To avoid this, I usually simply write additional logic inline as such:
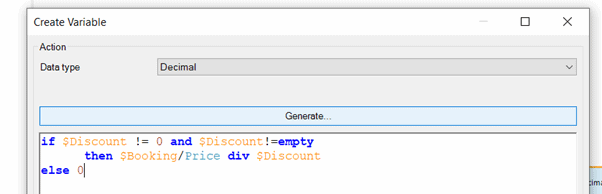
Of course, that’s if you are happy to return 0 in that case. In some situations, you might need to handle the exception differently with an exclusive split, for instance to display a valid error message to the user.
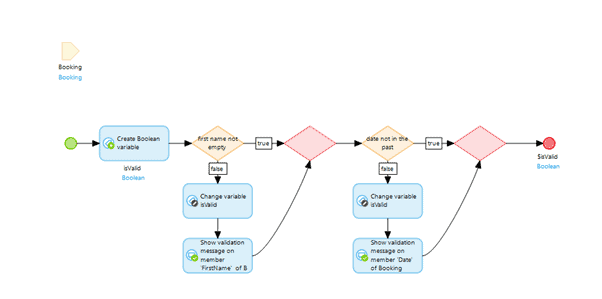
5. Validation rules
One way to avoid many empty returns and divides by 0, and countless other issues down the road, is to make sure your validation rules are watertight. This means insisting with your product owners that they spend time creating validation rules for each story in the acceptance criteria. Usually, they will need to think of three things:
- Is the attribute required?
- What is the absolute attribute range (minimum and maximum)?
- Is there a constrain between this attribute and any other? e.g. the start date cannot be later than the end date, etc.
Once we have those, we need to create for each form submission, a validation sub_microflow and include it in the save microflow:
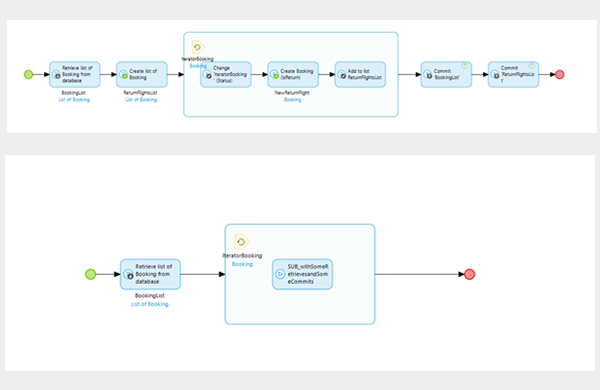
6. Performance
Performance is a large topic, but I have identified at least one common pattern that causes issues. I learned a while back to limit calls to a database inside a loop as shown on the left. However, what I also learned the hard way is to also check my sub-microflows within loops. While it is obviously the same problem, I found that it was easy to forget not to call the database in any sub_microflow that was nested inside a loop. This is especially true with several levels of nesting: One trick I used at the beginning to avoid doing this was to find some way to mark calls with a different colour. This way it is impossible to forget where calls to database happen:
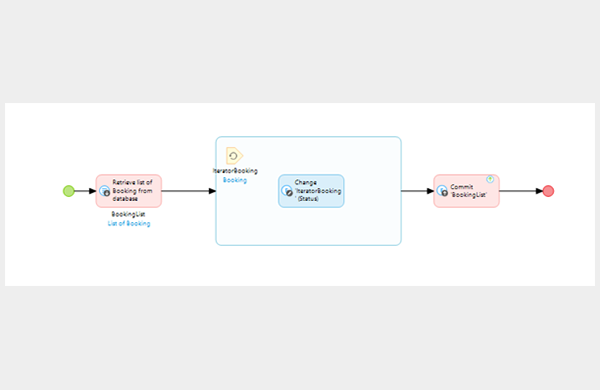
7. Navigation and saves
Recently I have built a number of workflow-type processes, for instance, with a user going through several steps of a questionnaire. I found that I needed to pay particular attention to navigation behaviour. Typically, there is logic to go from one step to the next.
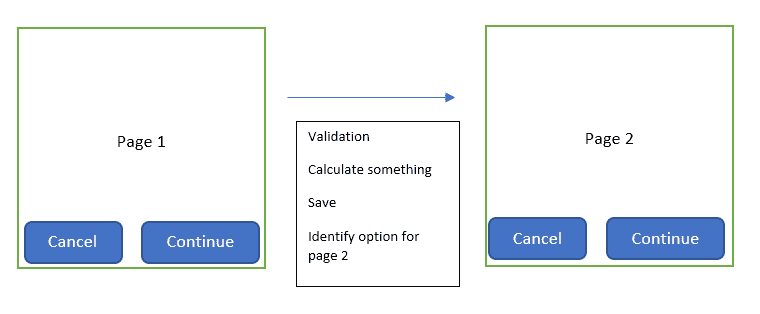
The user might request the ability to navigate back, or even to navigate straight to a page in the journey by clicking directly on the navigation breadcrumb menu. For example, say the user wants to jump from page 1 straight to page 4 of the journey. If they have changed anything on page 1, we need to make sure we run the validation again for page 1, re-do whatever calculation and ensure we save it.
What I usually build is a process where the user can go back to any previous page directly, but cannot go forward more than one page. This ensures that the flow of data is constrained by the path we have built, including all the necessary validations.
8. Delete behaviours
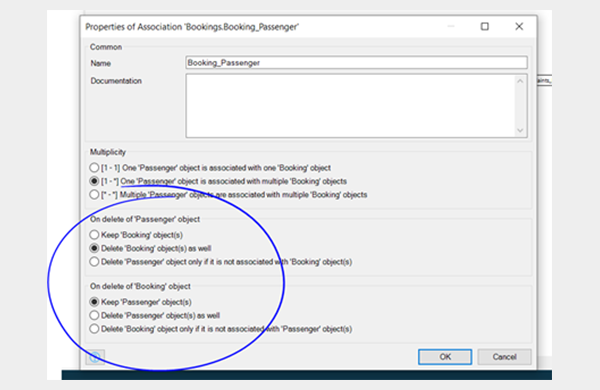
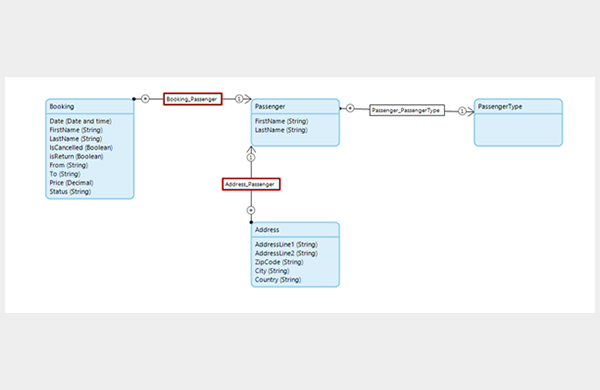
This is something I forgot many times at the beginning; establishing delete behaviours for all my associations. A delete behaviour determines what should happen to a child object when its related parent is deleted.
If the delete behaviour is missing, we quickly end up with lots of useless data no longer associated to any objects. We then find our users interacting with truncated data (e.g. bookings without passengers) which can create all sorts of bugs. You can quickly see all the delete behaviours in the domain model as they are highlighted in red.
9. Configuration tracking
A good proportion of bugs are due to missing a configuration step. By configuration I mean every step that occurs after deployment, such as updating an email template, or refreshing the Reflection Module in production. Forgetting a configuration step does happen. When you have been developing an app for 2 or 3 sprints since the last deployment, with each sprint including 20, sometimes 30 stories, it is easy to forget that somewhere in there, requirement 46 required you to build a small migration logic, which absolutely needs to be run as soon as the deployment happens.
I think the only way to keep track of those is to maintain a log. If you are using the Sprintr portal, you can add tags for deployment activities against each story when you complete them. You could also simply maintain a separate log in Jira or any other project management platform your team is using. What is essential is that everybody in the team has access to that log, and that all developers are committed to taking note of any deployment activity dependencies when they make a commit.
For more complex projects or more complex releases, you will need to build a deployment guide. This is mainly because deployment activities might have to be performed in a rigorous sequence. My advice is to keep at least half a day in the plan dedicated to consolidating the deployment guide. When the deployment itself has started, and the application is offline, there is little time to think about configuration steps. A deployment guide will solve this problem.
10. Hidden styles
There is more than one way to mess up the UI. One of the most common is not being able to identify where a style is set.
Mendix comes with Atlas UI, a UI framework built on top of Sass. On top of those pre-built classes, many customers ask us to create custom CSS classes to match their brand and desired UI. This is perfectly doable, but with several developers working on a project, and without a plan or structure, the styles can quickly become complex to handle. A typical bug appears when I apply new class, but it gets ignored by the browser, and never shows on the screen. Then begins the painful quest of looking in the browser developer tool to find where the style is being overwritten.
Here are my suggested rules to help avoid this:
- Use “Show Styles” to quickly see where styles have been applied. This will show, at a glance, which widgets have any particular style already applied to them, beyond the out-of-the-box styles that come with Atlas UI.
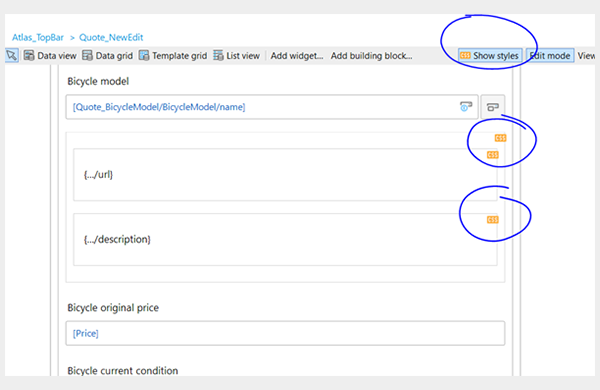
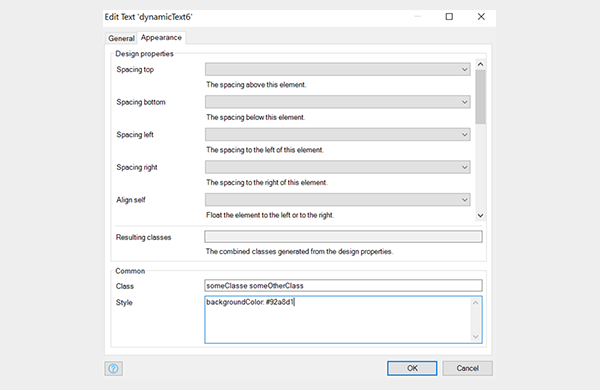
- Avoid inline styles. The properties of any widget offer the ability to add classes or inline styles. Classes present two benefits over inline styles. First, they are re-useable. This saves time and duplication of code and makes it easier to change the style in a single place moving forward. Second, they are much easier to keep track of. Custom classes can be nicely organised and catalogued in a single location, while inline styles are hidden all over the place.
- Make use of existing Atlas UI classes before creating any custom class. You can find the most important ones here https://atlas.mendix.com/p/helpers/7881299347899271
- When creating custom classes, organise them correctly. Any custom Sass classes are added in the project directory: {rootFolder}themestyleswebsassappcustom.scss
Instead of putting all custom classes in the same file, create different files to organise them, and import them in the custom.scss file. The custom.scss file at the end should only have the import statements, not actual styles. The various files can themselves be organised into folders. The system is up to you, as long as it is logical and agreed with the rest of the team. The idea is to make it obvious for a new developer on the project to find which folder, subfolder, and file likely contains the style for any particular component. In my experience it is much easier to appoint a single developer in the team to be in charge of UI and to maintain the custom classes rather than having everybody working on the same file.
Conclusion
I am not sure I’ll ever see a project entirely bug-free, no matter how simple. However, if you go through this exercise of finding the most common errors you make, you will get a chance to stumble upon new, more interesting bugs!
Related Blogs




Drag